MD-Blog_Web Creative
Stable Diffusionを使ってダミー画像を作ってみた 〜ネコ編〜
入社して来月でもう1年経とうとしているエンジニアのOYMです。東京のビルの高さに驚いて見上げていた頃が懐かしいです。(いまだに見上げていますが...)
さて、マークアップエンジニアはコーディングを行う上で「ダミー画像」を多用しますが、いつもグレー画像のプレースホルダーだと、単調すぎます!
せっかくならば可愛いネコちゃんを拝みながら仕事をしたいものです。
でもネコは飼ってないので写真がない...ならば、無いならば作ればいい!!
今回はWebエンジニアとして技術をキャッチアップするべく、最近よく聞くイラストAIというものに触れて、ダミー画像を作っていこうと思います。
今回生成するときに用いるツールはStable Diffusion web UI というものです。なぜこれを選んだかというと
- GUI操作でわかりやすく使える
- Macに対応している(intel CPU・Apple Silicon両方に対応)
- ローカルでの開発ができるため拡張性がある
という初めてでも使いやすいGUI操作を備え、Windows / Mac問わず開発ができるという幅広いサポートという面で選びました。
インストール
インストールはとても簡単で、Stable Diffusion web UIのリポジトリをクローンしてきて、下のコマンドをターミナルで叩くだけです。別途、Python3のインストールやPATHの設定などは事前に行う必要がありますが、こちらは省略させていただきます。
cd stable-diffusion-webui ./webui.sh
ちなみに今回私が開発した環境は下記です。
iMac 2020 intel CPU Python 3.10.9 stable-diffusion-webui v1.2.1
実際に生成
インストールが終わると、そのままターミナルにURLが表示されるので、アクセスするとGUIの操作画面が出てきます。本来は全て英語表記ですが、記事として解説がしやすいよう日本語化しております。
基本的にはこの画面に生成したい画像に沿ったワードを入力しして生成していくことになります。
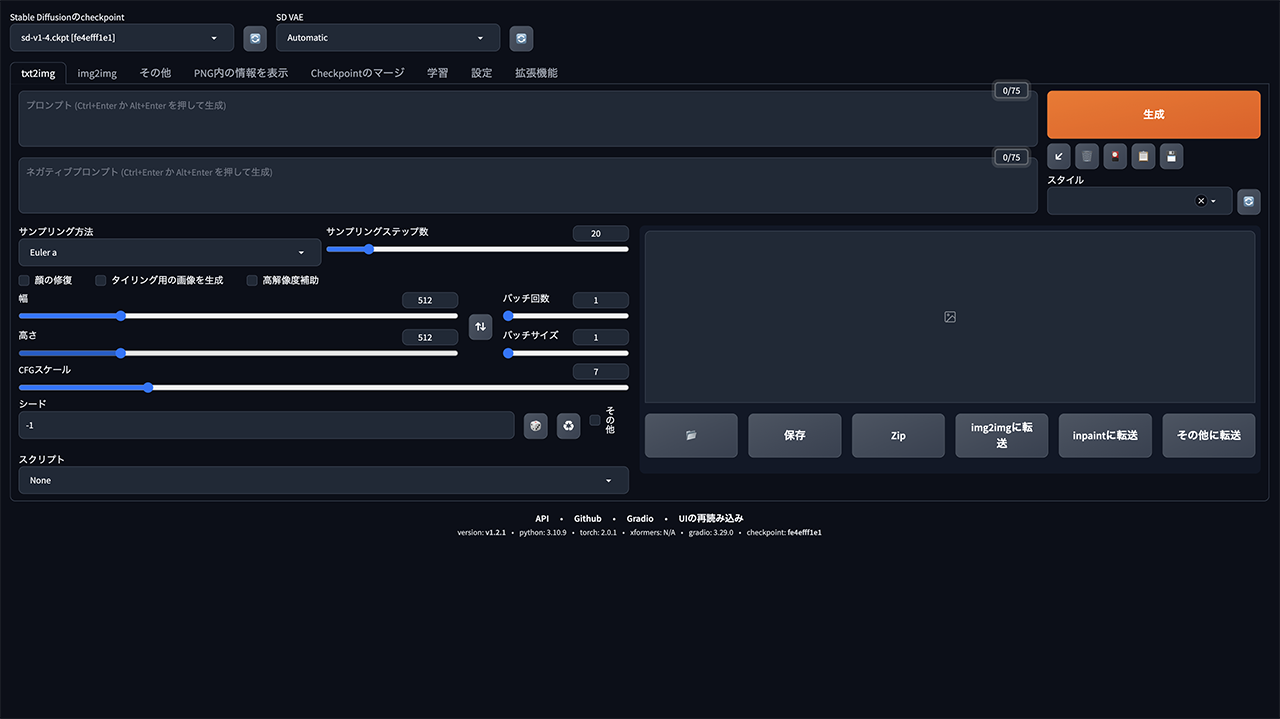
プロンプト
ここに生成したい画像のワードを入力していきます。
単語であったり文章でも読み取ってくれますが、現状では最大75ワードまでの入力となっています。
ネガティブプロンプト
画像生成するにあたって、自動的に生成されてしまうので意図しないものも描写される可能性があります。不要な物であったり、精度を上げるためにはネガティブプロンプトに入力することで生成を抑える役割を果たします。
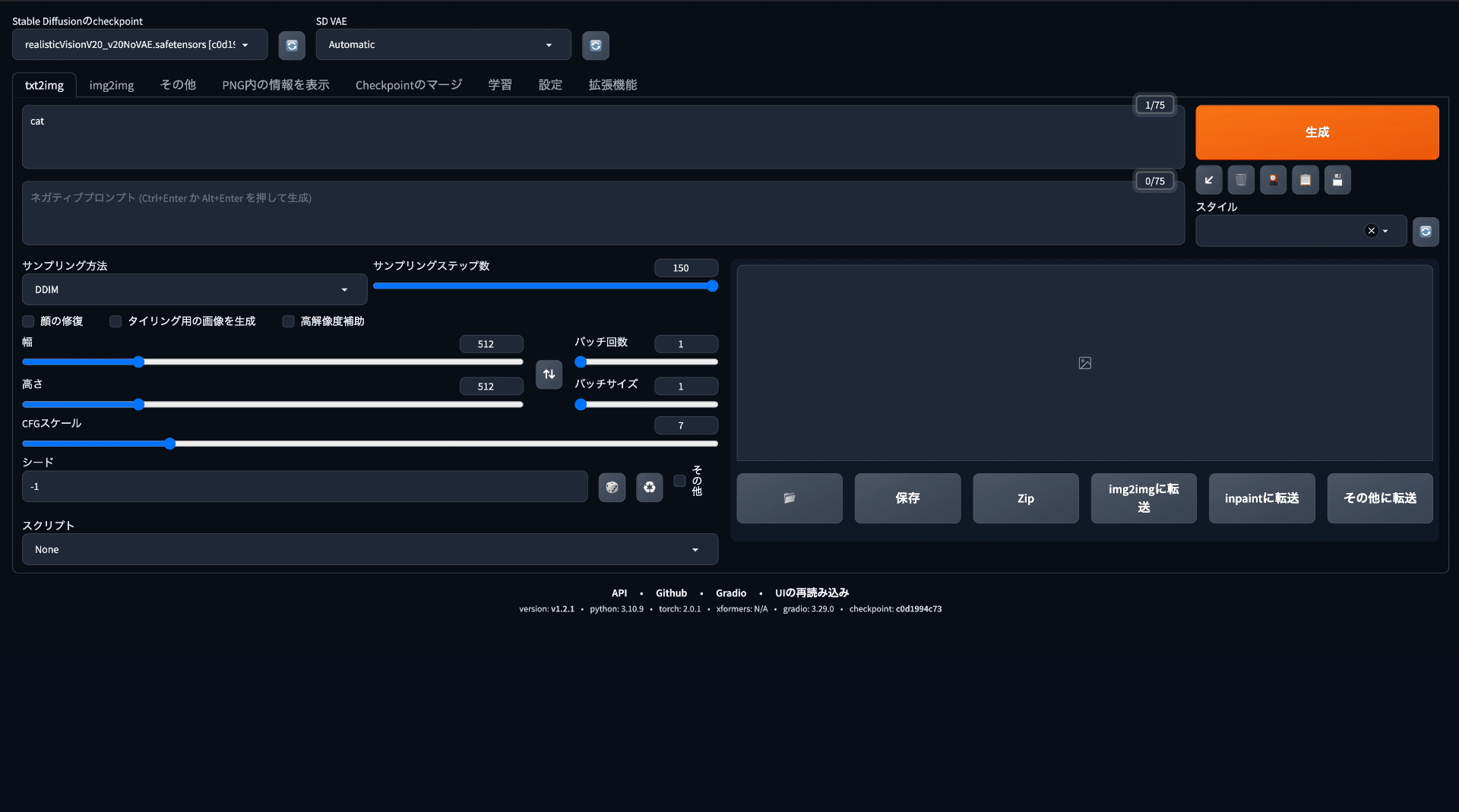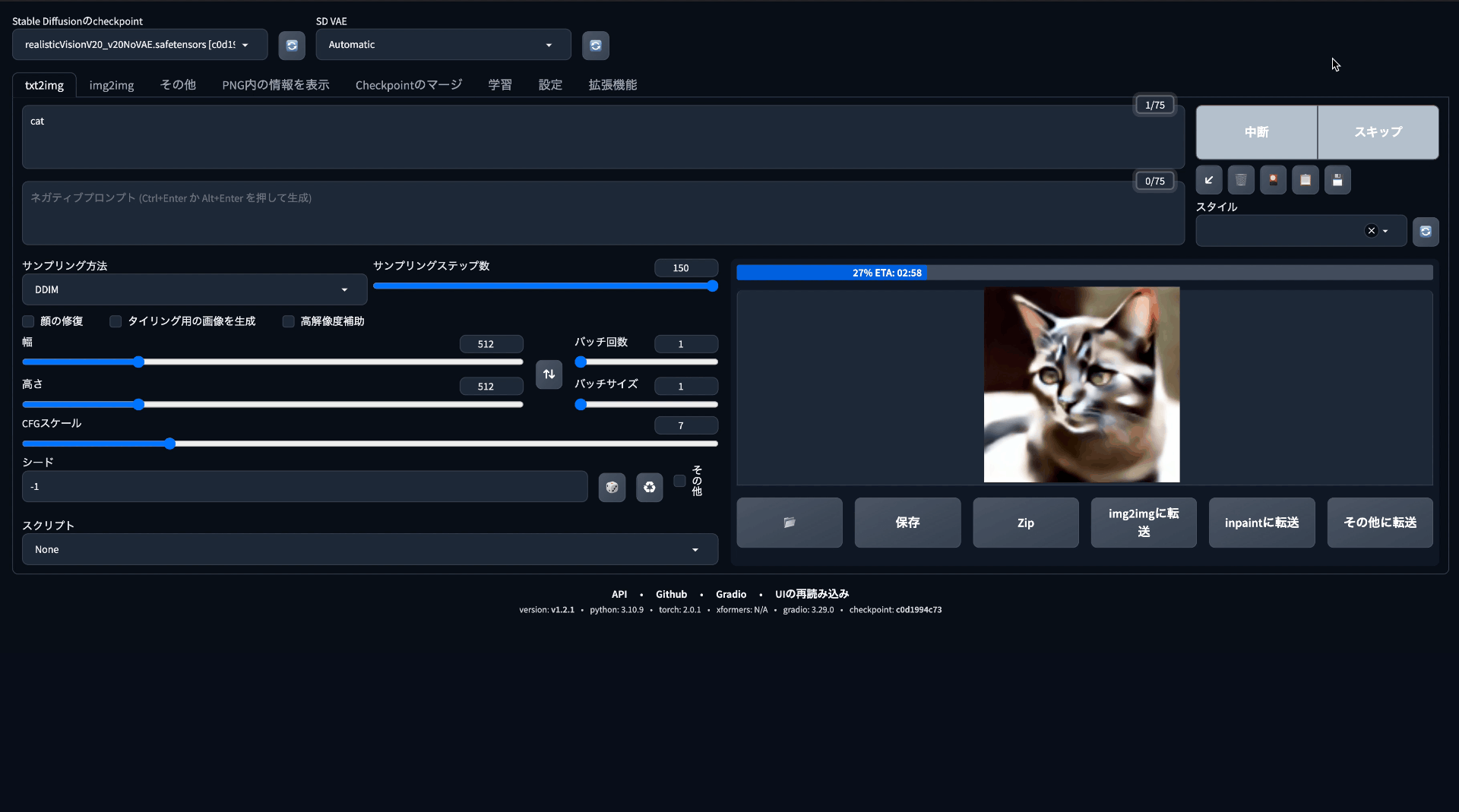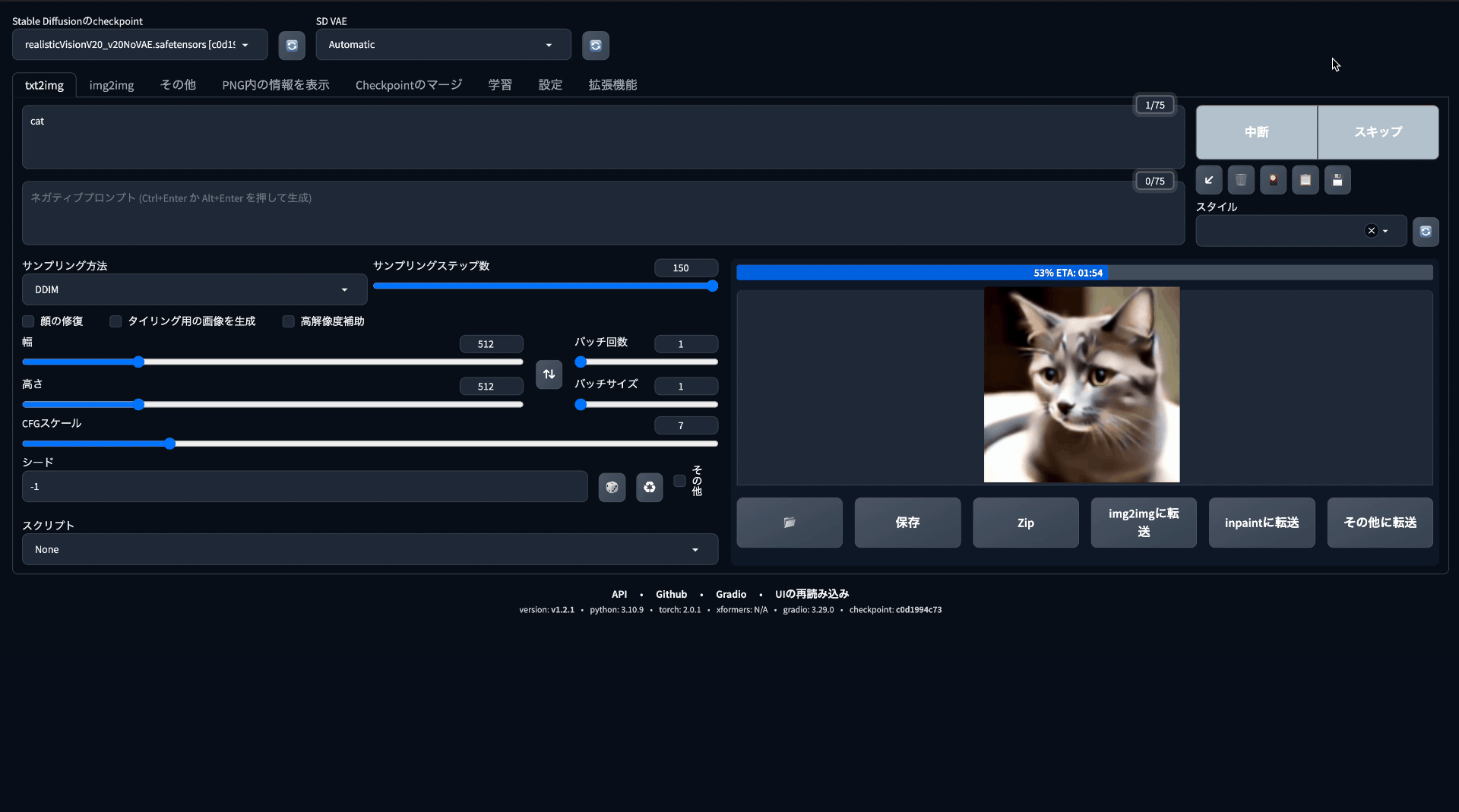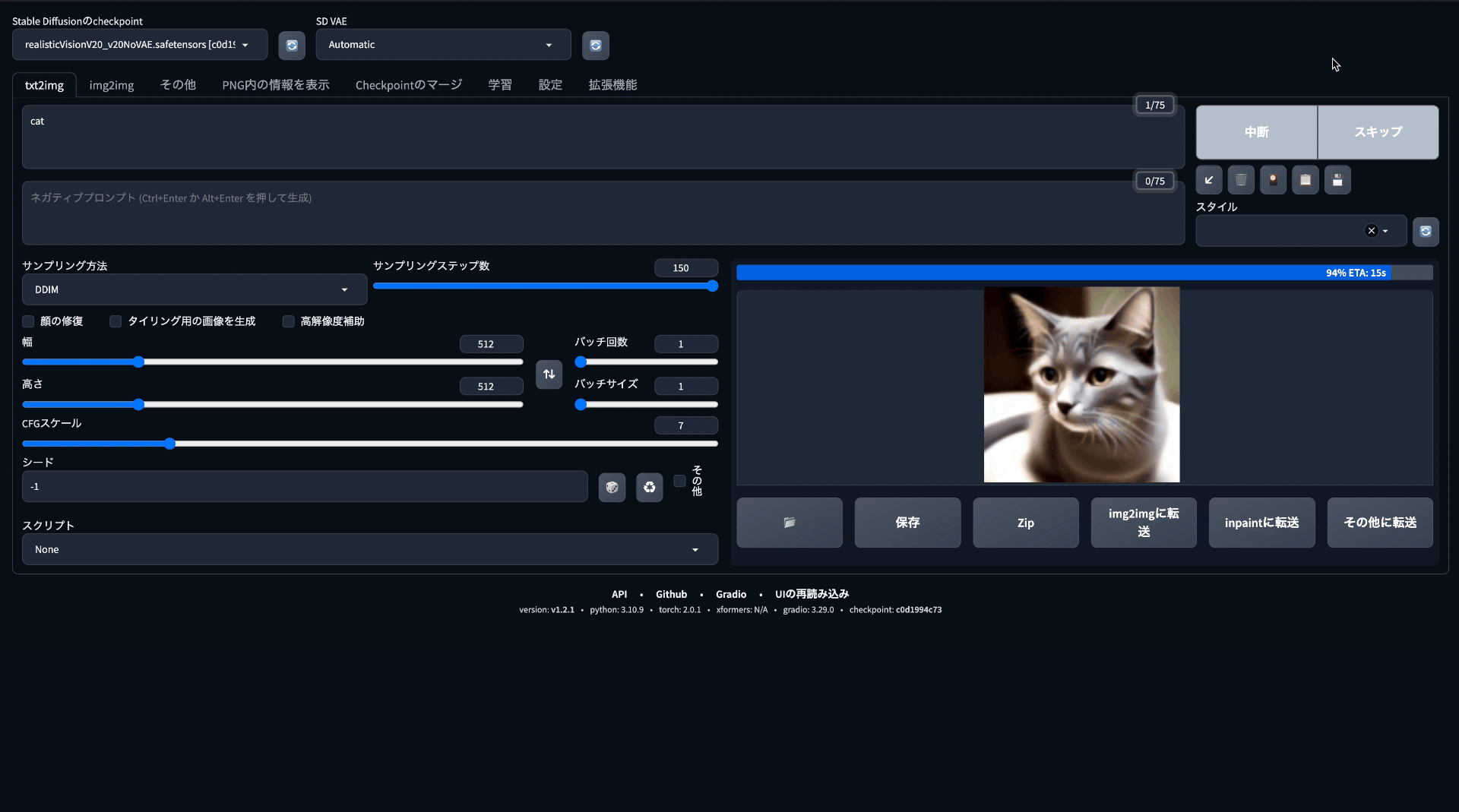
とりあえず何も考えずに* "cat" *と入力して書き出してもらいましょう。

プロンプト:cat モデル:sd-v1-4 サンプリングステップ数:20
デフォルトでも十分すごいです! どちらかというとイラスト風な見た目になりました。
目の色やバランスなどが多少不揃いなのはAIならではの処理だと思われます。
これをテキストや、追加学習を用いてチューニングを行うことで よりリアリティを求めることができます。
因みに生成中はこのように動いてます。
細かいオプションを使う
サンプリングステップ数
端的に説明すれば、ノイズ除去を行う回数です。
元は白いキャンバスに描写されるのではく、ノイズがたくさん入った画像から除去を行いイラストを生成させるというロジックなので、数が多ければ多いほど除去する回数が増え、結果的にクオリティの高いイラストが生成されるという仕組みです。
次にサンプリングステップ数をMAXの150にして出力してみましょう。
処理中は前と比べると生成されるまでの時間が圧倒的に長くなりました。

プロンプト:cat モデル:sd-v1-4 サンプリングステップ数:150
結果は上記のような感じです。
サンプリングステップ数を増やしたことにより、圧倒的に毛並みや質感が写真に寄った感じがします。よりリアルなイメージです。
Checkpoint
これがいわゆる「学習済みモデル」(以下、モデル)と言われる物です。
ここが一番重要なポイントで、選ぶモデル次第で絵柄やタッチなどが大きく変わるため、好みやリアリティが表に出やすい箇所になります。
今までは標準で実装されていたモデルを用いて生成を行ってましたが、他にも有志が作成したモデルが数多くあるため、今回はそのいくつかを比較しながら生成し、よりネコらしい画像を精査していきます。今回使用したモデルは以下です。

生成して思ったことは、モデルを変えるだけでこんなにも系統が変わるのかと思うくらい驚きました。左の2つはリアルな描写になり、右の2つはアニメチックなトーンで生成されました。そして、サンプリングステップ数も高ければ高いほど良いものができると思っていましたが、そうとも限らないかもしれないと感じました。ここは好みですね。
あとここまで生成してきて思ったことは、難しいことをせずにすごく簡単な操作だけで出来ちゃうという手軽さです。Pythonの学習とサンプリングを行わなくとも、ボタン1つで作れてしまうということに驚きました。これによってクオリティを上げるために用いるワードやモデルの選定といった方向に集中できるのは嬉しいことですね。
最終生成
それでは最終的に上で生成したモデルとプロンプトを更に考慮して、最高のネコを生成していきたいと思います。

プロンプト:a picture cat, Tuxedo, sun, detailed eyes, natural light, 4k, bestquality ネガティブプロンプト:text, human モデル:Realistic Vision V20 サンプリングステップ数:100
すんごい可愛いハチワレのネコちゃんが生成されました!
しかも超リアルですね!
最新の技術である「Stable Diffusion」に触れてみましたが、画像の自動生成がこんなにも簡単に出来ちゃう素晴らしさとクオリティの追求に思わずマークアップの手が止まってしまうほどでした。
今回は説明できなかった他の機能を用いれば、よりクオリティを上げることができそうですが、説明していくとキリがなさそうなので、どこかでまたお話しできればと思います。そして生成したイラストはSlackの動物好きチャンネルにてスタッフが共有させていただきました。
仕事を楽しくすることと、技術のキャッチアップは日々行なっていかないといけないものだなと改めて実感しました。
- Recent Entries
-
- 誰でも簡単に使えるポン出しアプリ(サンプラー) 「Klang2」をご紹介!【Part2】
- 画像を読み込ませるだけでコードを書かずにWebサイトを作れる「Windsurf」を試してみた
- 高額療養費制度を実際に利用してみた! 申請から給付までの流れ
- ライブ配信の仕事って実際どうなの? 現場のリアルを担当者が語る!職種別インタビュー!
- 実践に役立つ【ペルソナ設計】のポイントを、 WEBディレクターが真剣に考えてみました!
- ハイエースドライバーへの道 vol.2 〜免許取得から数ヶ月...ハイエース運転で味わった苦い経験と、社内で動き出した「運転手」のためのルールづくり〜
- 気づけば5年目!未経験ディレクターがここまで来た話
- アイディアを実現させる、MONSTER DIVEが創るライブ配信
- 大規模イベントで活躍中!Solidcom C1 Pro - Roaming Hub
- アルムナイ採用された側は、戻ってきた会社に何を感じたか
- MD EVENT REPORT
-
- MDの新年はここから。毎年恒例の新年のご祈祷と集合写真
- 2024年もMONSTER DIVE社内勉強会を大公開!
- 社員旅行の計画は「コンセプト」と「事前準備」が重要! 幹事さん必見! MONSTER DIVEの社内イベント事例
- 5年ぶりの開催! MONSTER DIVE社員旅行2024 "Build Our Team"!
- よいモノづくりは、よい仲間づくりから 「チームアクティビティ支援制度」2023年活動報告!
- 2023年のMONSTER DIVE勉強会を大公開!
- リフレッシュ休暇の過ごし方
- 勤続10周年リフレッシュ25連休で、思考をコンマリしたりタイに行った話。
- 俺たちのフジロック2022(初心者だらけの富士山登山)
- よいモノづくりは、コミュニケーションから始まる
- What's Hot?
-
- 柔軟に対応できるフロントエンド開発環境を構築する 2022
- 楽しくチームビルディング! 職場でおすすめのボードゲームを厳選紹介
- ライブ配信の現場で大活躍! 「プロンプター」とは?
- 名作ゲームに学べ! 伝わるUI/UXデザインのススメ
- 映像/動画ビギナーに捧げる。画面サイズの基本と名称。
- [2020最新版] Retinaでもボケない、綺麗なfaviconの作り方
- ビット(bit), バイト(Byte), パケット。ついでにbps。 〜後編「で、ビットとバイトって何が違うの?」〜
- 有名企業やブランドロゴに使われているフォントについて調べてみる。
- 算数ドリル ... 2点間の距離と角度
- 画面フロー/システムフローを考えよう!
- タグリスト
-
- #Webデザイン
- #JavaScript
- #MONSTER DIVE
- #映像制作
- #Movable Type
- #ライブ配信
- #CMS
- #ワークスタイル
- #MONSTER STUDIO
- #Webプロモーション
- #Web開発
- #アプリ
- #Creators Lab まとめ
- #Webディレクターのノウハウ
- #MTタグを極める
- #効率化
- #MD社内イベント
- #CSS
- #撮影
- #プランニング
- #Webクリエイティブ
- #オーサリング
- #クレバー藤原
- #コーディング
- #スマートフォン
- #Webディレクション
- #早朝がいちばん捗るヒト
- #PowerCMS
- #グラフィックデザイン
- #ストリーミング配信
- #WEBサービス
- #サマンサ先生
- #人事
- #Android
- #iPhone
- #Webメディア
- #まとめ
- #ディレクション
- #プログラミング
- #新入社員
- #HTML5
- #iOS
- #jquery
- #RIDE HI
- #UI/UXデザイン
- #プラグイン
- #ライブ中継
- #Adobe
- #アニメーション
- #プロジェクト管理